Малоценные или маловостребованные страницы: как с ними бороться
Содержание
- Виды малополезных страниц
- Чем плохи малополезные страницы?
-
Как найти малоценные или маловостребованные страницы
- Панели Вебмастера Яндекса и Google
- Парсеры и программы-анализаторы на примере SEO Screaming Frog
-
Яндекс Метрика и Google Analytics
- Примеры страниц для проработки

В мае 2020 года многие владельцы сайтов заметили, что страницы, раньше приносящие трафик, были массово исключены из поиска с формулировкой «Недостаточно качественная страница». Раздел с «НКС» появился в Яндекс.Вебмастере задолго до термина «малоценные страницы», и был важным инструментом анализа качества страниц сайта.

В этот же период и без того сложного 2020 года Яндекс анонсировал обновление, в результате которого неуникальные между собой страницы (карточки товаров, похожие услуги и т.д.) получили статус НКС. Больше всего от него пострадали интернет-магазины, имеющие множество сходных по шаблону и контенту страниц (карточек товаров). Но и ресурсы другого типа, например, агрегаторы, алгоритм не обошел стороной.
Оптимизаторы и владельцы ресурсов разрабатывали сложные стратегии минимизации НКС внутри сайта, и когда путь решения проблемы стал почти ясным, Яндекс выкатил новый алгоритм YATI, способный детально анализировать содержимое документа при помощи нейронных сетей (вслед за BERT у Google, выпущенный в 2019 году). НКС страницы при этом стали называться ММС - малоценные или маловостребованные.
Оценочные требования качества страниц стали еще более жёсткими. Буквально за один апдейт сайты с большим количеством страниц, попавших под определение «ММС», просели на 20-30 пунктов и не спешили возвращаться в ТОП.
Проблема актуальна для множества сайтов, беспокоит многих оптимизаторов и сегодня, в 2023.

По плану Яндекса, ММС — это страницы сайта, которые практически не получают трафика, вовлеченности или конверсии. Они не представляют большой ценности для пользователей или поисковых систем, и вероятность их ранжирования в результатах поиска чрезвычайно мала. Конечно, в реальности это не всегда работает так, как было задумано.
Кстати, у Google есть похожие метрики, правда, без использования официальной терминологии поисковиком. Термины родились в SEO-сообществе. Один из примеров - зомби-страницы (от англ. Zombie Pages). Идея зомби-страниц не совсем аналогична ММС, но влияние на хостовые факторы ранжирования сайта сходное. Также встречается термин Thin Content (или «тонкий контент»), который в целом описывает проблему малоценных страниц.
Виды малополезных страниц
Малоценными с очень высокой вероятностью станут следующие типы страниц:
- Пустые или полупустые страницы с небольшим количеством ценного контента, например, содержащие всего несколько предложений;
- Страницы с дублированным контентом, к примеру, если один и тот же товар интернет-магазина присутствует в нескольких категориях сайта, или же если карточки товаров имеют очень похожее содержание, несмотря на разные товары;
- Устаревшие страницы, содержащие неактуальную информацию, например, старые записи в блоге либо страницы продуктов, которые больше не доступны.
- Страницы низкого качества: с плохим дизайном, медленным временем загрузки или неработающими ссылками.
- «Страницы-сироты», которые не имеют ссылок на себя с других страниц сайта.
Страница признается маловостребованной, когда она:
- не соответствует поисковому запросу,
- оптимизирована под неправильную «неспросовую» формулировку запроса,
- совершенно не имеет спроса.
То есть страница исключается из поиска и нарекается маловостребованной, даже если не имеет технических ошибок и содержит контент, однако в поиске отсутствуют пользователи и запросы, которым она бы могла отвечать.
Чем плохи малополезные страницы?
- Снижение краулингового бюджета. Чем больше ММС, тем меньше скорость сканирования. Некачественные страницы не должны занимать место «правильных» страниц в индексе.
- Каннибализация ключевых слов. Страницы одного сайта могут конкурировать по одному и тому же поисковому запросу, и мешать друг другу в результате.
- Уменьшение авторитетности сайта. При накоплении критической массы ММС (30%-35% от всех страниц сайта), видимость ресурса снижается, бизнес теряет лиды, в результате чего авторитетность ресурса с точки зрения Яндекса снижается.
- Пессимизация поведения пользователей. Если страница действительно не представляет ценности, пользователи с большей вероятностью покинут сайт, если не найдут там ценного для себя контента, что приведет к высокому показателю отказов и негативному пользовательскому опыту.
Краулинговый бюджет - это лимит на сканирование страниц поисковым роботом. У каждого сайта есть свой определенный бюджет.
Таким образом, наличие на сайте значительного количества малозначимых или маловостребованных страниц негативно сказывается на поисковой оптимизации (SEO), потому что они не предоставляют пользователям практически никакой ценности, затрудняют конверсию и наносят ущерб репутации сайта. И несмотря на регулярную и стратегическую работу во всех других направлениях, усилия по продвижению могут не иметь достойного результата.
Поисковые системы отдают предпочтение сайтам с высококачественным контентом, который является актуальным и ценным для посетителей. Такие ресурсы имеют больше шансов занять хорошие позиции в результатах ПС, улучшить видимость и трафик.
Как найти малоценные или маловостребованные страницы
Панели Вебмастера Яндекса и Google
Самым простым и достоверным способом будет просмотр специального отчета в Яндекс Вебмастере. Этот метод доступен для тех, кто не глубоко погружен в науку о SEO.

Итак, инструкция:
- Необходимо зайти в Яндекс Вебмастер под своим аккаунтом (а точнее, под тем аккаунтом, где находится продвигаемый проект).
- Открыть отчет "Индексирование" → "Страницы в поиске" → Вкладка "Исключенные", затем установить статус "Малоценная или маловостребованная страница".

- Просмотреть график и отметить, какой процент имеют ММС.

- Выгрузить результат и точечно проанализировать попавшие в отчет страницы.
Если процент "токсичности" менее 10%, можно не переживать, более 20% – следует напрячься, выше 30% – бьем тревогу.
В Google Вебмастере (Google Search Console) также можно посмотреть страницы, признанные малозначимыми. Только статус у них будет другим: "просканирована, но пока не проиндексирована". В принципе, это можно считать аналогом ММС Яндекса.
В Google Search Console вам понадобится:
Открыть отчет "Индексирование" → "Страницы" → Вкладка "Не проиндексированы", затем в перечне найти статус "Страница просканирована, но пока не проиндексирована".

Далее проваливаемся в подраздел и мониторим найденные страницы.

Их тоже можно выгрузить, чтобы лучше проанализировать и выявить общие проблемные моменты.

Парсеры и программы-анализаторы на примере SEO Screaming Frog
Чтобы найти малоценные страницы в SEO Screaming Frog, можно использовать следующие шаги:
1. Перед сканированием сайта зайдите в раздел Configuration, затем выберите пункт Content и Duplicates.

Далее надо поставить галочку в чек-боксе «Enable Near Duplicates».

Зачем это делается? По умолчанию SEO Spider автоматически определяет точные дубликаты страниц. Однако для определения "близких дубликатов" необходимо включить специальную настройку. Тогда SEO Spider будет определять близкие дубликаты при 90% сходстве. Это можно настроить и для поиска контента с более низким порогом сходства.
2. Перед проверкой можно также настроить блок Config → Content → Area.

При настройке, как на скриншоте выше, SEO Spider исключает из процесса парсинга элементы навигации и футера, чтобы сосредоточиться на основном содержимом. Однако не каждый сайт построен с использованием этих элементов HTML5, поэтому при необходимости вы можете уточнить область содержимого, используемую для анализа, выбрав "включить" или "исключить" HTML-теги, классы и идентификаторы в анализе.
3. Теперь можно ввести адрес вашего сайта в поле "URL" для начала сканирования и подождать, пока сайт не спарсится целиком.
4. После анализа сайта необходимо найти поле Content, где можно увидеть количество слов на каждой странице.

Малое количество слов может также быть маркером малоценных страниц.
5. Чтобы посмотреть точные дубликаты, ныряем в фильтр Exact Dublicates:

А вот близкие дубликаты требуют пост-анализа.
Для этого заходим в Crawl Analysis и нажимаем кнопку Start:

Для проверки зон, где парсер ищет близкие дубликаты, нужно зайти в Configure, и проверить, какие настройки выбраны:

После завершения анализа индикатор выполнения будет равен 100%, а в фильтрах больше не будет сообщения Crawl Analysis Required.
6. В итоге мы увидим данные по тем URL, содержание которых превышает выбранный порог сходства, остальные останутся пустыми. В данном случае на сайте их всего шесть.

7. Для дальнейшего анализа дубликатов (в нашем случае - близких дублей) требуется кликнуть на проверяемый URL, а в нижнем меню выбрать пункт Duplicate Details.

Если в нижнем поле кликнуть на анализируемую страницу, то в окне справа появится информация чем схожи и чем они отличаются.
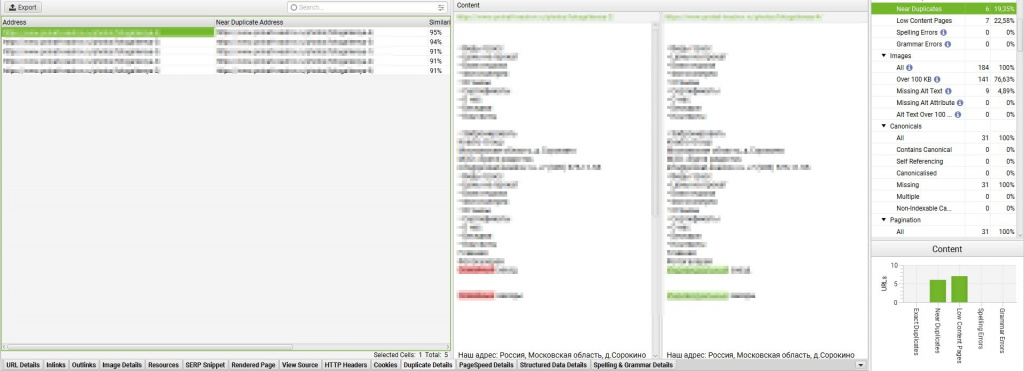
8. Выгрузка результатов осуществляется через меню Bulk Export → Content.

Резюмируя, отметим, что во Фроге есть два фильтра, позволяющих нам найти дубликаты:
- Точные дубликаты. Этот фильтр показывает страницы, идентичные друг другу, используя алгоритм MD5, который вычисляет «хэш» значение для каждой страницы, которое можно увидеть в колонке «хэш». Эта проверка выполняется по полному HTML страницы. Она покажет все страницы с одинаковыми значениями хэша, которые полностью совпадают.
- Близкие дубликаты. Этот фильтр показывает похожие страницы, основываясь на настроенном пороге сходства, используя алгоритм minhash. Алгоритм работает с текстом на странице, а не с полным HTML, как в случае с точными дубликатами.
А теперь лайфхак! Уточните порог сходства и повторно запустите анализ.
Возможно на вашем сайте найдутся еще страницы, близкие по содержанию.
Чтобы отыскать дубли, есть еще одна возможность, которую предоставляет инструмент SEO Frog. Он позволяет найти на вашем сайте дубли h1, title и description. Их наличие на сайте также ведет к дублированию контента и нерациональному расходу краулингового бюджета.
Такие дубликаты можно найти в соответствующих блоках, а затем выгрузить для анализа и корректировки.


Выгрузку можно сделать из блоков, нажав кнопку Export.
Также можно выгрузить все метатеги и заголовки страниц, а затем найти дубликаты средствами Microsoft Excel.
Яндекс Метрика и Google Analytics
Малоценные и маловостребованные страницы в системах аналитики можно обнаружить по плохим поведенческим факторам.
В Яндекс Метрике заходим в отчет "Содержание" → "Страницы входа", где постранично анализируем процент отказов, глубину просмотра и время на сайте.

Если страницы имеют 100% отказов и другие низкие метрики, с ними явно что-то не так, и они требуют более глубокого анализа.
Маловостребованные страницы находятся по количеству визитов на них в разрезе как минимум квартала (лучше брать период от года).

Если страница имеет мало визитов (в сравнении с общим трафиком, приходящимся на сайт), то она скорее всего несет мало пользы, что требует принятия решения о целесообразности ее наличия на сайте.
Для поиска ММС страниц в Google Analytics алгоритм схожий. Требуется зайти в отчет "Поведение" → "Контент сайта" → "Все страницы / Целевые страницы". Далее провести анализ страниц по показателю отказов и количество просмотров страниц.

Во всех системах аналитики есть возможность выгрузки результатов, благодаря чему вы легко получите список страниц, с которыми требуется провести дополнительную работу.
Примеры страниц для проработки
Похожие карточки:


Полупустые страницы:


Страницы-результаты фильтрации с малой выборкой товаров:


Варианты правок или как решить проблему ММС
После получения списка малоценных и маловостребованных страниц его необходимо проанализировать и отфильтровать по различным признакам. Обычно страницы разделяют на группы по типу контента. В итоге получаются следующие категории: карточки товаров, разводящие страницы каталога, страницы услуг, портфолио, статьи.
Далее эти категории можно еще сегментировать по найденной проблеме. Здесь будет применяться деление на дубли, пустые/полупустые страницы, неактуальный, устаревший контент и пр.
Правильная группировка подобранных страниц позволит сфокусироваться на конкретных категориях, провести более глубокий анализ каждой из них и выбрать максимально эффективные способы борьбы с проблемой, что в конечном итоге поможет улучшить общую видимость сайта в поисковой выдаче.
Итак, существуют разные методики по работе с малоценным или малополезными контентом. Но все они сводятся к принятию одного решения - оставлять ли страницу для индексации либо закрывать ее.
Если приятно решение, что страница нужна, то требуется ее дооптимизация:
- Обновление или доработка контента на странице. Возможно, контент устарел, и стоит обновить его с учетом новых тенденций в вашей нише.
- Оптимизация страницы под конкретный запрос: если страница не соответствует поисковому запросу или оптимизирована под неправильную формулировку, то стоит исправить ее соответствующим образом.
- Устранение дублирующихся H1, title и description: дублирование метатегов может отрицательно сказаться на ранжировании страницы в поисковых системах.
- Улучшение юзабилити: если у пользователей есть проблемы с навигацией или с конверсионными кнопками на странице, то устранить эти проблемы.
Чем можно разнообразить контент на странице?
- SEO-текст - написание текста, который описывает товары/услуги, их преимущества и возможности использования. Текст должен быть качественным, уникальным и содержать ключевые слова, связанные с запросами пользователей.
- Отзывы - размещение отзывов клиентов на странице может повысить доверие и убедить посетителей совершить покупку. Отзывы должны быть разные и получены с разных источников (например, отзывы на сайте, в социальных сетях, на сторонних платформах).
- Видео - добавление видео может помочь в продвижении товаров/услуг, а также в улучшении пользовательского опыта. Видео могут быть обзоры товаров, демонстрация работы продукта, инструкции по использованию и т.д.
- Смена шаблона - изменение дизайна и визуальной составляющей страницы может сделать ее более интересной и привлекательной для посетителей. Например, можно изменить цветовую гамму, использовать более современный шрифт, добавить анимации и т.д.
- Динамический контент - например, "Похожие товары", "Рекомендации" могут помочь в повышении продаж и увеличении взаимодействия с посетителями. Такой контент может быть добавлен в виде блоков на страницу, а также подобран автоматически на основе просмотров и покупок других пользователей.
Очень важно отслеживать эффективность внесенных изменений, чтобы оценивать их работу, и корректировать стратегию в зависимости от результатов.
Исключение страницы из процесса индексирования
В случае если «дооптимизировать» страницу бессмысленно, либо же оптимизация уже была произведена, но спустя время не дала никакого результата, требуется выбрать один из методов.
- Склейка.
Она может осуществляться за счет 301 редиректа или настройки канонических ссылок.
Редирект 301 позволит перенаправить старую малоценную страницу на более ценную, возможно на новую или же на страницу уровнем выше в структуре сайта, которая имеет хороший трафик и поведенческие.
Каноничесские ссылки помогают указать поисковикам, какая страница является основной, а какая дубликатом или второстепенной. Это помогает сократить дубликаты и улучшить качество страниц. - Закрытие от индексации. Если страница не приносит ценности для пользователя или поисковых систем, ее можно закрыть от индексации. Для этого можно использовать настройки файла robots.txt, мета-теги noindex, nofollow или x-robots-tag.
Закрытие этими методами имеет свои нюансы:
robots.txt - это текстовый файл на сервере, который указывает поисковым роботам, какие страницы и разделы сайта имеют право индексировать, а какие нет. Файл robots.txt позволяет экономить краулинговый бюджет, так как поисковые системы, с большой долей вероятности, не будут индексировать страницы или разделы, которые вы указали в файле robots.txt. Однако стоит помнить, что файл robots.txt не является средством блокировки доступа к странице. Он лишь указывает поисковому роботу, что ему делать с этой страницей.
meta-robots - это метатеги, которые можно добавить на страницу сайта, и которые указывают поисковым роботам, как обрабатывать эту страницу. Тег meta-robots позволяет указывать, нужно ли индексировать страницу, следует ли следовать ссылкам на этой странице и т.д. Это удобно, когда на сайте есть разные типы страниц, и некоторые из них не должны индексироваться. Тег meta-robots, в отличие от robots.txt, воспринимается поисковиками более строго, кроме того, регулирует не только запрет на индексацию, но и на сканирование документа.
X-Robots-Tag - это HTTP-заголовки, которые можно отправлять с сервера вместе с ответом на запрос поискового робота. Заголовок X-Robots-Tag указывает поисковому роботу, как обрабатывать страницу. Этот метод закрытия от индексации удобен, когда нельзя изменить HTML-код страницы, например, для закрытия PDF-файлов от индексации.
Удаление страницы с сайта. Если страница не приносила никакого трафика, и не является значимой, ее можно удалить (напомним, что правильный код ответа сервера для несуществующей страницы — 404 Not Found). Для ускорения удаления страницы из поиска используются инструменты вебмастеров Яндекс и Google, в которых есть соответствующие разделы для удаления страниц из индекса. Даже если страница не несла никакого трафика, рекомендуем настраивать с нее 301 редирект.
Важно! Перед закрытием от индексации или удалением страницы необходимо проверить, не является ли она источником полезного трафика на сайте, чтобы не потерять посетителей. Удаление любой страницы может повлиять на SEO-рейтинг сайта, поэтому необходимо хорошо обдумать это решение и принять меры, чтобы минимизировать потери.
В качестве заключения
Не стоит начинать переживать сразу, увидев статус «Малоценной или маловостребованной страницы» на вашем веб-сайте. Это не является ограничением - поисковые системы не налагают на него фильтры или баны. ММС указывают на то, что необходимо внести улучшения на ваш ресурс. Если поисковый бот при следующем обходе определит, что страница стала более востребованной и ценной, то она обязательно будет включена в поисковую выдачу.


